서비스
ArkData는 데이터의 안정성을 위한 재해복구 시스템 구축, 마이그레이션, 실시간 빅데이터 및 백업을 위한 IT 서비스를 제공합니다.

Real-time Bigdata
Real-time Bigdata
아크데이타는 카프카 구축을 통해 Any DB/Application 복제가 가능한 데이터 통합 및 사용자 환경에 맞는 배포 서비스를 제공합니다.실시간 빅데이터 통합으로 스템 간 통합이 간소해지며 서비스간 연속성이 높아집니다.
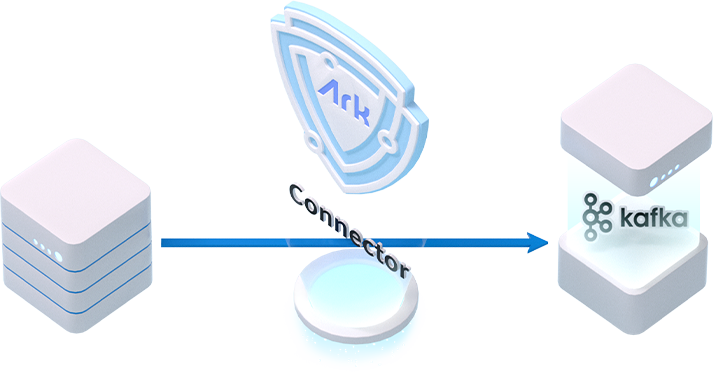
서비스 소개
-
- 서비스 간의
연속성 향상 - 시스템 간 통합이 간소해지며 서비스간 연속성이 높아짐
- 표준 인터페이스를 확보하여 구축과 관리가 쉬움
- 초고속, 분산, 확장 가능한 플랫폼 구축
- 카프카 구축을 통해 실시간 빅데이터 통합 지원
- 서비스 간의
-
- 데이터 정합성 보장
- 실시간 스트리밍 데이터 처리로 데이터 활용성 증가
- 대용량 데이터에 대한 통합과 분석이 쉬워 새로운 비즈니스 가치를 창출
- 데이터 볼륨, 사용자 증가에 유연한 대처 및 비용 절감 가능
- 실시간 빅데이터 통합으로 업무 효율성 증가
-
- MSA 구현
(Micro-Service Architecture) - 데이터의 미세한 처리를 통한 어플리케이션 서비스의 분산 가능
- 독립적인 개발과 배포 가능
- 서비스 유연성 확대
- 카프카 구축
- MSA 구현
-
- 이기종 데이터 통합
- 다양한 데이터 형식 지원
- 연관된 업무 속성의 이기종 데이터 통합하여 연속적 데이터 흐름 유지
- 온프레미스와 클라우드 간의 데이터가 손쉽게 연동 가능
- 실시간 빅데이터 통합
Why ARK
통일되지 않은 지연 연계솔루션
- 지연 연계로 실시간 분석과 정책 결정이 어려움
- 관리 비용 및 인력 과다
- 새로운 서비스 적용이 어려움
일원화된 데이터 수집 및 배포 환경
- 간소화된 데이터 연계
- 서비스 간의 연속성 향상
- MSA 구현으로 유연성 확대
구축 방법
-
01
요구사항 분석

빅데이터 플랫폼을 구축하기 전에 기업이나 조직의 요구사항을 분석하고 목표를 설정합니다. 데이터 양과 유형, 처리 성능, 보안 요구사항 등을 고려하여 구체적인 구축 방향을 정합니다.
-
02
기술 선택
어떤 기술과 플랫폼를 사용할지 결정합니다. 카프카 기반의 이벤트 스트리밍, 클라우드, 데이터베이스 선택 등을 고려하여 최적의 플랫폼을 결정합니다.
-
03
데이터 수집 및 저장

대량의 데이터를 수집하기 위해 데이터 소스와 연결하고, 데이터 수집 방법을 결정합니다. 배치 처리와 실시간 스트리밍 처리를 모두 고려하여 데이터를 효율적으로 수집하여 저장 방법을 선택합니다.
-
04
데이터 처리
저장된 데이터를 처리하고 분석하기 위해 적절한 도구를 선택합니다. Apache Hadoop, Apache Spark, 머신 러닝 라이브러리 등을 사용하여 데이터를 가공하고 인사이트를 도출합니다.
-
05
데이터 시각화

분석 결과를 시각적으로 표현하여 데이터의 특성과 경향을 파악할 수 있도록 합니다. 시각화 도구나 대시보드를 활용하여 시각화 작업을 진행합니다.


